

Raw data contains various errors and is incomplete to read. Therefore, such data needs to be transformed into a readable format, which organizations can use to derive meaningful insights. The data wrangling process allows the raw data to be converted into an accurate format to ensure high-quality data.
This saves many organizations and helps them make informed decisions based on data. So, today, let’s see what is data wrangling and how it helps businesses maximize their efficiency.
What is Data Wrangling?
Data wrangling is also known as data munging and differs from data mining. Data wrangling is a data analytical process that involves cleaning, structuring, and enriching raw data into a readily usable format for analysis. The process requires precise data cleaning by removing and correcting errors, inconsistencies, and duplication.
Properly structuring data into a tabular format makes the data analysis process easy. The definition of what is data wrangling continues beyond here. It includes merging and formatting data sets to prepare data for further data analysis, machine learning projects, modeling, and exploration. So, it is a systematic and transformative way of structuring messy and unstructured data.
Why is Data Wrangling Important in 2024?
The data wrangling process continues to grow in 2024 for various reasons. Today, many professionals spend 73% of their time wrangling data. This shows that data processing is indispensable, and it helps businesses to make concrete bases by making timely and informed decisions.
Some of the reasons why data wrangling is significant in 2024 are as follows:
- Volume and variety of data: Today, companies can generate data from the internet, social media, IoT devices, and various other sources. This data needs to be managed and analyzed correctly to increase performance exponentially. Data wrangling is the fastest means to handle these data and ensure data efficiency.
- Advanced analytics and Artificial Intelligence: Advancements in analytics and AI have caused high demand in data processing. Data wrangling has also become much easier with some efficient tools to advance the models, clean them accurately, and convert them into better-structured forms. Data wrangling will help in future AI and machine learning projects to maximize the profitability of businesses.
- Faster decision-making: In this fast-paced world, you must make quick decisions and stay competitive. Data wrangling ensures that businesses make appropriate decisions based on data. It prepares data so that companies can analyze them and gain information quickly.
- Compliance and data governance: Businesses are required to maintain data privacy and usage regulation as per GDPR and CCPA guidelines. The data wrangling process enables you to comply with the rules by cleaning and structuring data appropriately.
Key Benefits of Data Wrangling
There are various benefits of the data wrangling process. You need to know these critical benefits and know what data wrangling is. Furthermore, to get hands-on experience in practical aspects and strengthen your fundamentals, join CCSLA’s Big Data Analysis and Machine Learning with R eLearning course.
Enhanced Data Quality and Accuracy
Data wrangling ensures quality and does not hinder the integrity of data analytics. Data accuracy is maintained throughout the process and enhances the reliability of insights derived from it.
Raw data contains errors, inconsistencies, and missing values, hindering executive decision-making. Executives can make more informed decisions with better analysis and data-wrangled sets.
Improved Analytical Efficiency
Data wrangling streamlines the data preparation process. It helps make more efficient data analysis by leveraging automation processes for routine tasks. With employed advanced data, organizations can allocate optimum resources at the preparatory stages and maximize the analytical efficiency at core tasks.
This way, efficiency gains traction, and analysts explore more data and complex sets to frame better insights.
Machine Learning and Advanced Analytics
Advanced analytics and machine learning models need clean and structured data for the effective functioning of their analysis. The data wrangling process transforms raw data into a readable format with machine learning models and analytical tools to facilitate sophisticated analysis.
The predictive analytics, consumer segmentation, and trend analysis processes can shape the application of refined data into more accurate situations.
Integration from Multiple Sources
Today, sources are available in abundant form. Data is available from IoT devices, social media, enterprise systems, web networks, etc. The data wrangling process helps businesses integrate data from various sources and transform them into standardized formats to resolve discrepancies in the organization. The created cohesive dataset allows executives to make informed decisions with a more holistic view.
What Steps Does the Data Wrangling Process Involve?
Now that we know what is data wrangling, we should understand what steps it involves. The crucial steps intend to transform the raw data into a format ready for analysis. Data transformation is essential for digging meaningful insights and influencing the decision-making and strategic planning process of business.
With better data wrangling tools, data wrangling becomes a lot easier. Let’s check the steps involved in data wrangling.
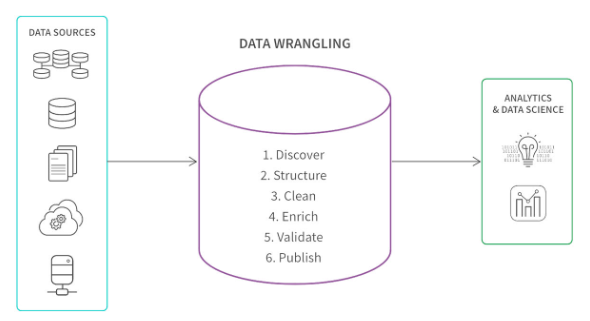
Discovering
The first step of the data wrangling process is collecting data from various sources. These sources include files, external APIs, databases, or web scraping. Collecting data involves identifying sources, assessing their quality, and figuring out how to structure them.
The primary goal of the discovery process is to build a good foundation for data preparation by recognizing its potential threats and opportunities.
Structuring
Once you collect data, you can organize the raw data into a readable format. You can organize the data in various formats like structured (SQL databases), semi-structured (JSON, XML files), or unstructured (text, images, or documents).
Structuring needs to be in a more analysis-friendly format so that executives can quickly gain insights. Structuring data includes reshaping data and handling missing values. This way, data can be presented in a more standardized format, and the scope of manipulation is minimized.
Some essential structuring elements are parsing data into structured fields, normalizing its consistency, and transforming data from text to lowercase for analysis.
Cleaning
The cleaning process involves removing errors, inconsistencies, and duplication. This eliminates the possibility of skew analysis, resulting in better-prepared data sets. Removing irrelevant data and correcting mistakes contributes to the cleaning process. Dealing with missing values helps remove and estimate statistical methods, too.
Cleaning is a crucial process that addresses the anomalies and impacts data reliability. Cleaning data ensures data accuracy and reliability through the downstream process.
Enriching
Enriching data involves enhancing data with some additional inputs that give context and depth. This may include merging datasets, extracting errors, and incorporating national data sources.
The goal is to increase the original dataset and make it more comprehensive with valuable points. If you add data, make it structured and clean them first.
Validating
Validating data ensures the reliability of processed data is on point. It checks the inconsistencies, verifies data integrity, and confirms the data adherence to set standards. Furthermore, validation helps build your confidence and establish the dataset’s accuracy. Validating ensures that data accuracy and quality are not compromised.
It retains data integrity and ensures foreign keys match in a database. It also follows a quality assurance test that meets the predefined standards and rules of the validating process.
Publishing
Once the validation process is done, a more curated and validated dataset is produced for analysis. The dissemination and documentation of data are made for executives to glance at and gain insights from it. The final wrangled data is then stored in a data repository like a data warehouse to make it accessible for reporting and analysis.
The storage is secure, and the queries and analysis parts are organized. After that, it is converted into a readable format. For publishing data, documentation is prepared with a detailed outlook of how data was refined, transformed, and audited.
What are the Different Tools for Data Wrangling?
Data scientists and analysts use different tools for the data-wrangling process. After knowing what is data wrangling, it becomes essential to understand the various tools used by data scientists and analysts.
Here is the list of tools that you, too, can use for data wrangling:

Excel Power Query
Excel power query is a basic tool for filtering, sorting, and basic computations. The alternative to Microsoft Excel is Google Spreadsheets. It makes it accessible and more manageable for simple tasks.
Tabula
This versatile tool can obtain data from various files and documents, irrespective of their formats. It is used to extract data from any source without any issues. It helps data analysts to collect and structure data in the most appropriate format.
Trifacta
This is a cloud-based data management tool. It offers intelligent data cleaning and transformative features that help data scientists and analysts clean and change datasets. Trifacta is ideal for large-scale businesses that are equipped with complex data and require a significant capability to follow data wrangling tasks.
Altair Monarch
It is an Altair-based platform that offers self-service data preparation techniques. The Altair Monarch tool is accessible on desktops and can easily connect to multiple data sources. You can also connect it to cloud-based servers and big data to operate it.
Alteryx Designer
The Alteryx Designer tool has intuitive features and the best user-friendly interface. It can easily be connected with cloud-based data and applications. It helps clean extensive data and stores the data securely in a repository like a data warehouse. Furthermore, it can extract data from warehouses or any other sources.
Datameer Enterprise
Datameer Enterprise offers data analytic lifecycle and engineering options. This tool covers all the processes that are related to data management. From data ingestion and preparation to exploration, it contains all. The tool has access to more than 70 sources for ingestions of all types of data, whether structured, semi-structured, or unstructured.
Anzo
Anzo is a tool that helps users find, connect, and blend data seamlessly. It connects internal and external data sources, which are highly useful for organizations. In this tool, you can add layers of data for cleaning, preparing semantic models, aligning, and accessing control. Anzo’s user-friendly approach allows businesses to prepare better-analyzed datasets.
TMMData
This tool is a foundational platform that includes data integration, preparation, and management functionality. It allows tools to deploy cloud-based data and helps manage large chunks of data efficiently. The works in hybrid mode, too, for better optimization and efficiency of performance regardless of your location.
OpenRefine
This is an automated data tool which is used to clean data sets. It requires a good knowledge of programming and machine learning skills. OpenRefine can also be used for large data-cleaning projects that require expertise.
Python/R
The two most important languages for programming are Python and R. Both these tools offer extensive libraries and packages for data wrangling. Pandas and Dplyr are libraries and packages that help data analysts in analysis. These languages are flexible and have the power to manipulate complex data tasks.
Data Wrangling Career Path
If you’re curious about what data wrangling involves in practice, consider pursuing a career in this field. There are various roles available within data wrangling, each offering numerous job opportunities with competitive salaries.
To enhance your prospects, you can start by taking relevant certification courses, especially if you already have a background in computer science from your undergraduate or postgraduate studies. This specialized training will equip you with the skills needed to excel in data wrangling roles.
Certification Courses
Some of the certification courses you can choose are:
- Google Data Analytics Professional Certificate
- Microsoft Office Excel (2019-2016-2013): Advanced
- CompTIA Data+
- Big Data Analysis and Machine Learning with R eLearning
Job Opportunities
Here are some popular roles that you will be offered after becoming a professional data wrangler:
- Data scientist or data analyst: This role requires the collection, transformation, and building of data with the help of data analysis tools. You may also be required to collect data and create presentations or reports to satisfy the business goals.
- Data warehouse: This role needs skills to manipulate and combine data. You may also perform tech-related administration tasks.
- Database administrator or architect: In this role, you need to create and organize systems of business to keep data secure and safe. Some additional tasks may include backing up data and ensuring the database is not under threat and is free from errors.
Salary Outlook
The salary in the data wrangling field is high since the demand for such professionals is increasing. The salary may depend on roles, experience, and individual qualifications. However, the average salary outlook for some common roles is as follows:
- Data scientist: Rs. 898,897
- Data warehouse developer: Rs. 468,690
- Database administrator: Rs. 523,115
Conclusion
The data wrangling process is used in many fields. Some common cases of data wrangling in the industry are deleting unnecessary data, removing errors from the datasets, and finding the missing datasets. Businesses also use this process to merge two data sets into one for analysis. The process fixes the inconsistencies and errors so that executives make better decisions to maximize business efficiency. The job of data wrangling is highly essential and in demand.
So, if you are planning to begin your career in this field, you can start with CCSLA Data Analytics & Engineering Bootcamp. It will help you gain hands-on experience in projects with job placement assistance and one-to-one mentorship. With this bootcamp, you can get a chance to become a certified trainer with a cutting-edge curriculum.




