
What is Hashing in Cyber Security and How Does It Work?
Hashing has become ingrained in cyber security measures that individuals and organizations carry out on a routine basis. This technique chops up data into a scrambled output that appears random and meaningless. However, the same data will always generate the exact same hash output. This enables cyber security professionals to lock down data and detect any tampering by comparing the before and after hashes.
In this article, we will break down what hashing entails in plain terms and outline why it provides an extra barrier against cyber threats. We’ll also dive into different types of hash functions, illustrating how subtle changes in input data trigger major differences in the hashed output.
The Origins of Hashing
The notion of hashing was pioneered in the early 1950s by Hans Peter Luhn, a researcher at IBM. Although Luhn did not invent the specific algorithms used today, his foundational work ultimately catalyzed the inception of hashing.
When colleagues presented Luhn with the challenge of efficiently searching a list of chemical compounds encoded in a cryptic format, he recognized the need for enhanced information retrieval in these types of scenarios. Consequently, Luhn spearheaded the process of indexing as a solution.
Over the subsequent 30 years, scientists expanded on Luhn’s creation of indexing to develop a technique for encoding plaintext known as hashing. The hashing process necessitates two key components: a plaintext value and a hashing algorithm. Applying the hashing algorithm to the plaintext value yields a hashed output.
As hashing evolved, it became an indispensable tool for applications ranging from data integrity checks to password storage. In summary, pioneering work in indexing ultimately precipitated foundational advances in the field of hashing.
What is Hashing?
Hashing is the process of mapping data of arbitrary size to fixed-size values called hashes using a mathematical algorithm known as a hash function. The hashing algorithm is designed to be a one-way function, meaning that it is extremely difficult to reverse the process and determine the original input from the hash value alone. The input data is often called the message, and the hash value it maps to can be thought of as a digital fingerprint of that original data.
The main purposes of hashing are to quickly and uniquely identify data, detect duplicate data, or distribute data across available storage resources. Hashing is used in many areas of computing and cryptography because it enables looking up or storing data efficiently.
Some key characteristics of cryptographic hashing algorithms used in cybersecurity include:
- Deterministic: The same input will always generate the same hash value.
- Non-reversible: It is practically impossible to determine the original input from the hash value, a process known as a preimage attack.
- Collision resistant: It is extremely difficult to find two different inputs that give the same hash value, known as a collision attack.
- Avalanche effect: A small change in the input results in significant changes to the hash value.
What is Hashing Used For?
Hashing is utilized in various cybersecurity applications:
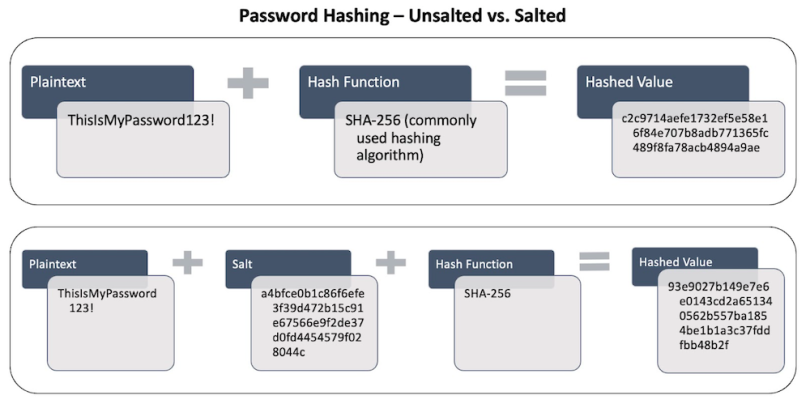
- User password storage: Passwords are hashed and the hashes are stored, rather than storing the passwords in plain text. This protects the passwords if a system is breached.
- Data integrity: Hash values of files or network packets can be calculated. Any changes will modify the hash value, indicating tampering.
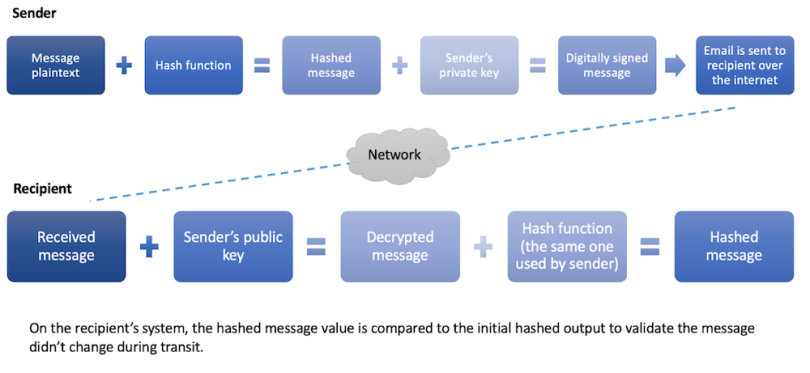
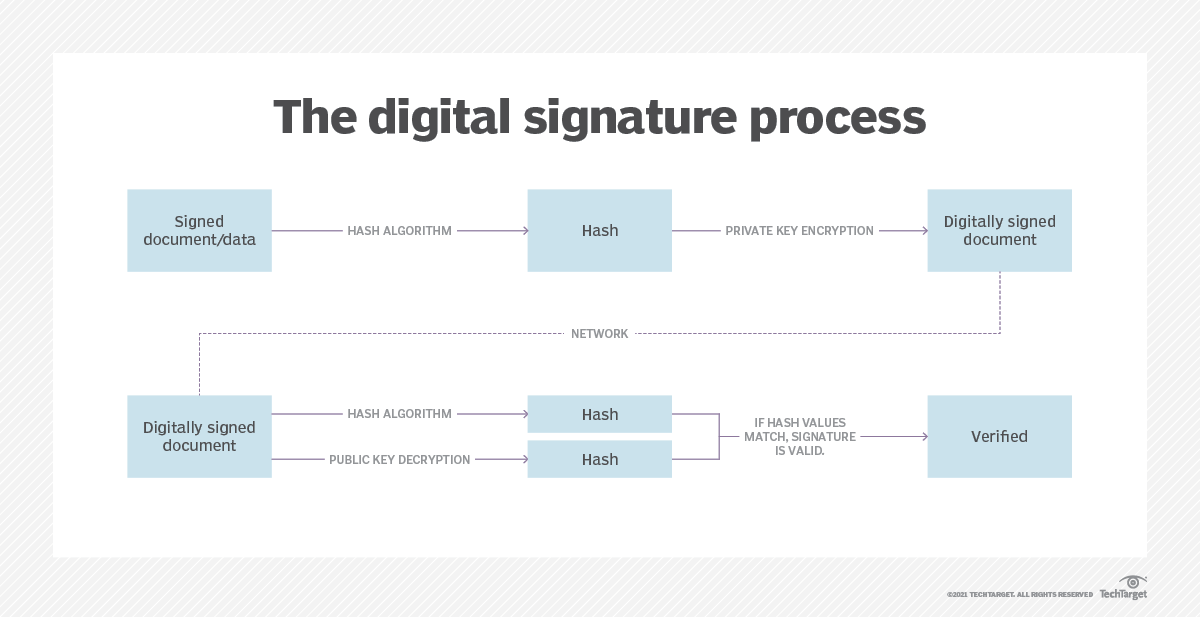
- Digital signatures: Hashing a message before encryption provides authentication and integrity. The hash is encrypted with the sender’s private key.
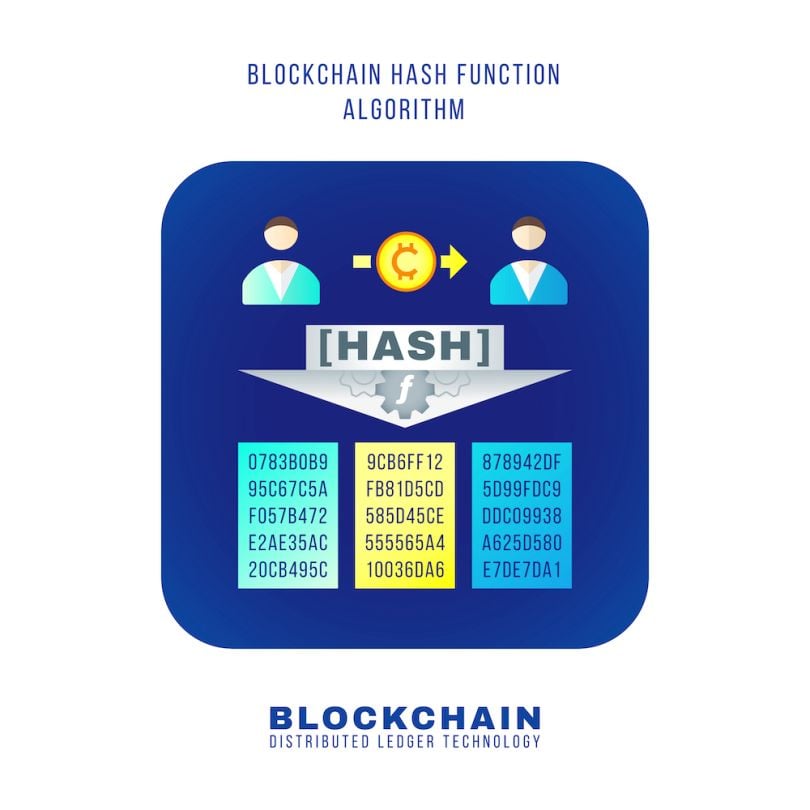
- Blockchain: Transactions are hashed and stored in blocks to provide immutable records of events.
Hashing Algorithm Examples
Some of the most popular hashing algorithms include the following:
- Secure Hash Algorithm1(SHA-1)
SHA-1 is a cryptographic hash function published by the National Institute of Standards and Technology (NIST) in 1995. It produces a 160-bit hash value known as a message digest.
SHA-1 is based on principles similar to those used by Ronald L. Rivest of MIT in the design of the MD4 and MD5 message digest algorithms. It takes an input and produces an irreversible, fixed-size 160-bit output.
SHA-1 relies on the Merkle–Damgård construction to process a variable-length message into a fixed-length output. Despite its wide adoption, SHA-1 has demonstrated vulnerabilities, prompting a migration to successors SHA-2 and SHA-3.
- Secure Hash Algorithm 2(SHA-2)
SHA-2 is a set of cryptographic hash functions designed by the NSA and published by NIST as a successor to SHA-1. They include SHA-224, SHA-256, SHA-384, SHA-512, SHA-512/224 and SHA-512/256.
SHA-2 relies on the Merkle–Damgård structure to transform a variable-length input into a fixed-length output. It utilizes a one-way compression function that maps data of arbitrary size to a fixed size.
All SHA-2 variants produce digests of 224, 256, 384 or 512 bits. SHA-256 and SHA-512 are novel hash functions computed with 32 and 64 bits words respectively. They use different shift amounts and additive constants but their structures are otherwise virtually identical.
- Secure Hash Algorithm 3(SHA-3)
SHA-3 is the latest member of the Secure Hash Algorithm family released by NIST in 2015. Unlike SHA-1 and SHA-2, which are based on the Merkle-Damgard construction, SHA-3 is based on a sponge construction and uses the Keccak algorithm. It has a completely different internal structure from its predecessors.
The sponge construction absorbs input data and then permutes it into a fixed-length hash output. This aims to provide increased resistance to attacks, such as length-extension and partial-message collisions. SHA-3 provides the four fixed output lengths of SHA-2 and serves as a direct replacement.
- MD2
The MD2 algorithm was designed by Ronald Rivest in 1989. It produces a 128-bit hash value. MD2 is optimized for 8-bit computers, though it works on 32-bit computers as well.
The algorithm uses a non-linear compression function that converts a variable-length input into a 128-bit output. The security of MD2 relies on a complex multiplication step within the compression function.
MD2 enables quick computations while minimizing potential weaknesses due to its simple design. However, MD2 is vulnerable to collision attacks, so it is no longer used in cryptographic applications.
- MD4
MD4 was also designed by Rivest in 1990 as an extension of MD2. It operates on 32-bit words rather than 8-bit bytes. The algorithm performs three rounds of processing on each 16-word block of the input message.
It produces a 128-bit hash value similar to MD2. MD4 was designed for increased speed on 32-bit CPUs. However, collision attacks were identified against it, allowing forged digital signatures to be created. This led to MD4 being superseded by more secure hash functions.
- MD5
MD5 was published by Rivest in 1991 as an improved version of MD4. It operates on 32-bit words and applies four rounds of processing per block. The additional round boosts security while maintaining high performance.
It produces a 128-bit hash like MD4. MD5 gained widespread use due to its speed and simplicity. However, extensive vulnerabilities have been found relating to collision resistance, allowing unauthorized parties to create files with matching hashes. This led to MD5 being deemed insecure for most cryptographic purposes.
How Does Hashing Work in Cyber Security?
Hashing is the process of using a cryptographic hash function to irreversibly scramble plain text data into hashed output of fixed length. The hash function is a one-way function, meaning the hashed output cannot be reversed to obtain the original plain text input.
For example, when a user creates an account on a website, they choose a password. This password is put through a hashing algorithm, such as SHA-256, to generate a hashed version of the password. The original password is discarded, and only the hash of the password is stored in the database.
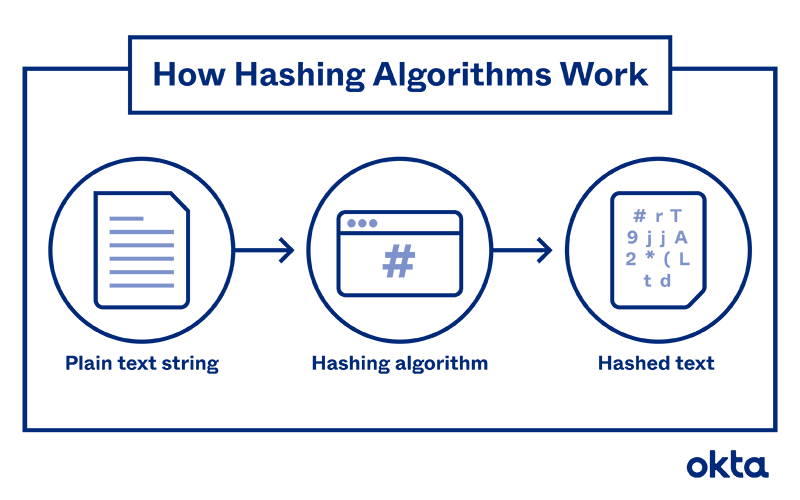
When the user attempts to login later, the password they enter is hashed using the same algorithm(SHA-256), and the resulting hash is compared to the stored hash. If the newly generated hash matches the stored hash, the user is authenticated. The password is never stored in plain text, so if the database is compromised, the attacker only gains access to the hashed passwords, not the actual passwords.
Hashing strengthens cybersecurity by protecting sensitive data like passwords. Even if hacked, the hashed passwords are difficult for attackers to crack because hashes are one-way functions.
Conclusion
Hashing is a crucial cybersecurity technique that helps protect sensitive data and ensure integrity. Widely used hashing functions like MD5, SHA-1, and SHA-256 underpin authentication and verification across many cybersecurity applications. As cyber threats grow more advanced, the role of cryptographic hashing will likely expand as well.
To equip yourself with in-demand cybersecurity skills, including expertise in cryptography and hashing, check out CCS Learning Academy’s comprehensive cybersecurity courses. Whether you’re new to the field or looking to advance your career, CCS offers flexible online programs to help you master cyber defense, ethical hacking, risk management, and more.
With hands-on labs and projects modeled on real-world systems, you’ll gain practical experience to thrive as an information security professional. CCS’s respected instructors and dedicated career resources will set you up for success in this high-growth industry. Enroll now and take the first step toward an exciting future in cybersecurity!
FAQs
Q1: What is hashing in the context of cybersecurity?
Hashing in cybersecurity refers to the process of converting any input (usually a piece of data or a file) into a fixed-length string of characters, which is typically a hexadecimal number. This output is unique to the specific input data, and even a small change in the input will result in a significantly different hash value. Hashing is widely used in cybersecurity to ensure data integrity, verify passwords, and create digital signatures.
Q2: How does hashing work to ensure data integrity?
Hashing ensures data integrity by generating a unique hash value for a given set of data. When the data is transmitted or stored, its hash value is recalculated and compared to the original hash value. If the two hash values match, the data is intact. Even a minor alteration in the data will result in a completely different hash value, alerting the system to potential tampering or corruption.
Q3: What is the role of hashing in password security?
Hashing plays a crucial role in password security. Instead of storing actual passwords in a database, systems store their hash values. When a user attempts to log in, the system hashes the entered password and compares it with the stored hash value. This way, even if the database is compromised, hackers cannot retrieve the original passwords, enhancing security.
Q4: How does hashing contribute to digital signatures in cybersecurity?
Hashing is an integral part of creating digital signatures. When a sender wants to sign a document or a message, the document’s hash value is generated. The hash value is then encrypted with the sender’s private key, creating the digital signature. The recipient can verify the sender’s identity and the document’s integrity by decrypting the signature with the sender’s public key and comparing the resulting hash value with the recalculated hash of the received document.
Q5: Is hashing reversible? Can you retrieve the original data from a hash value?
No, hashing is a one-way function, meaning it is not reversible. Once data is hashed, the original input cannot be retrieved from the hash value. This one-way nature of hashing ensures security, as even if someone obtains the hash value, they cannot reverse-engineer it to obtain the original data without significant computational resources.
Q6: What are some commonly used hashing algorithms in cybersecurity?
There are several widely used hashing algorithms in cybersecurity, including MD5 (Message Digest Algorithm 5), SHA-1 (Secure Hash Algorithm 1), and SHA-256 (part of the SHA-2 family). However, due to vulnerabilities found in MD5 and SHA-1, SHA-256 and other SHA-2 variants are more commonly used today due to their enhanced security features.
Q7: Can hashing be used for large files and documents, or is it only suitable for small pieces of data?
Hashing can be used for both small and large files. While it’s true that generating hash values for large files can be computationally intensive, modern computing systems are capable of handling this process efficiently. Hashing large files ensures data integrity and allows for quick verification of the file’s contents without the need to compare the entire file, making it practical for various cybersecurity applications.
Q8: How does salting enhance the security of hashed passwords?
Salting involves adding a random value (salt) to the password before hashing it. The salted password is then hashed and stored in the database, along with the salt value. Salting enhances security by ensuring that even if two users have the same password, their hashed passwords will be different due to the unique salts. This prevents attackers from using precomputed tables (rainbow tables) to crack hashed passwords, significantly strengthening password security.
Q9: Can hashing be used to detect duplicate files efficiently?
Yes, hashing can be used to detect duplicate files efficiently. By generating hash values for files and comparing these values, systems can identify duplicate files without having to read and compare the entire file contents. This method is commonly used in data deduplication processes and file management systems, improving efficiency and saving storage space.
Q10: How does hashing contribute to blockchain technology and ensuring the integrity of transaction data?
In blockchain technology, each block contains a hash of the previous block, creating a chain of blocks linked by hash values. This linking ensures the integrity of the entire blockchain. Once a block is added to the chain, altering any data in a previous block would change its hash, invalidating all subsequent blocks. This makes it extremely difficult to tamper with transaction data, providing a secure and immutable record of transactions in blockchain systems.





