

Snowflake is a cloud-based data warehousing solution that provides a fully managed service for storing, processing, and analyzing data. It is designed to be highly scalable, flexible, and cost-effective, making it an ideal choice for organizations of all sizes.
Snowflake architecture is based on a unique separation of compute and storage, which allows for highly scalable and elastic data processing. It uses a virtual warehouse to provide compute resources, while data is stored in a centralized location in a highly compressed format. This architecture allows for fast and efficient data processing, with the ability to scale up or down as needed.
Snowflake offers a range of services including data warehousing, data lake architecture, and data sharing. Snowflake’s architecture is designed to enable the creation of data lakes within its platform. Multiple data sources are continuously providing an immense volume of data, which can be thoroughly explored, refined, and analyzed using a data lake.
Exploring The Snowflake Architecture

Snowflake Architecture Layers – Source
Snowflake, as an Amazon Web Services (AWS) partner, provides assistance for AWS-endorsed data warehousing. One of the features that Snowflake offers is support for AWS PrivateLink, which allows customers to establish a secure connection with their instance without relying on the public Internet via the cloud-based data platform
On the other hand, Both Snowflake and cloud providers like the Google Cloud Platform and Microsoft Azure have experienced a growing demand from customers to operationalize Snowflake for better performance and reliability as well.
Here are some key points regarding the architecture of Snowflake:
Hybrid Architecture
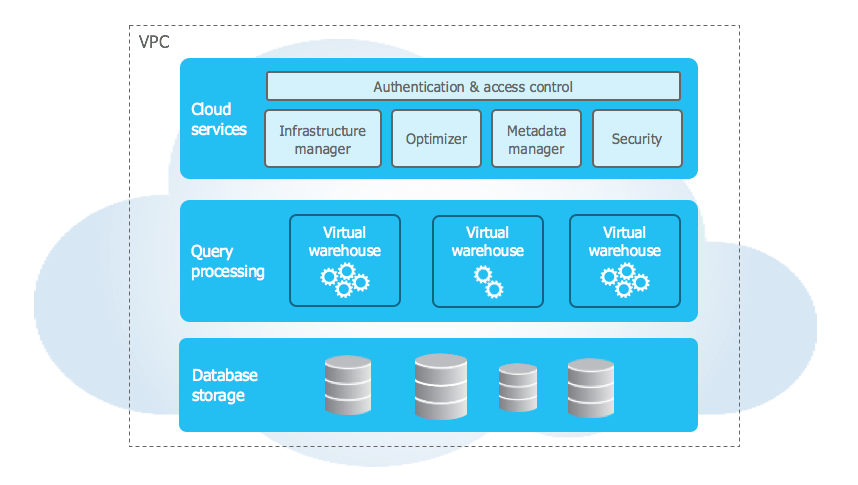
Snowflake’s architecture combines elements of shared-disk architecture and shared-nothing database architectures to form a hybrid model. It relies on a central data repository to store large amounts of persistent big data that can be accessed from any of its compute nodes. Additionally, Snowflake comprises three distinct layers: the Storage Layer, Compute Layer, and Cloud Services Layer.
Storage Layer
Snowflake’s highly optimized and compressed micro-partition database storage layer ensures high performance by ensuring fast and efficient data retrieval and analysis by organizing data into several micro-partitions
Compute Layer
The compute layer in Snowflake is where the data processing takes place. It includes virtual warehouses that are created on demand for specific workloads. These virtual warehouses can be scaled up or down depending on the processing requirements.
Cloud Services Layer
The cloud services layer provides the necessary services for managing the Snowflake environment, such as authentication, metadata management, and query optimization in the cloud storage layer.
Multi-cluster Shared Data Architecture
The Snowflake data cloud uses a multi-cluster shared data architecture that allows for seamless scaling of data storage and processing power. This architecture allows Snowflake to handle large volumes of data while providing high concurrency and performance.
Separation of Storage and Compute
The Snowflake database separates the storage and compute layers, which allows users to scale their compute power independently of their storage needs. This separation provides greater flexibility and cost-effectiveness compared to traditional data warehousing solutions.
What are Virtual Warehouses?
Snowflake offers a unique data warehouse solution using virtual warehouses. These are computing clusters that are used to process queries against data stored in Snowflake. Each virtual warehouse is made up of one or more compute nodes, which can be scaled up or down as needed to handle varying workloads. This allows for highly elastic and scalable data processing, without the need for manual management of compute resources.
Types of Virtual Warehouses and Their Use Cases
Virtual Snowflake data warehouse architecture is an essential part of Snowflake architecture that provides computational resources for querying and parallel processing of data in the cloud by acting as a cloud data warehouse.
Below are the two types of virtual warehouses and their use cases in Snowflake’s unique architecture:
Standard Virtual Warehouse:
A standard virtual warehouse in Snowflake architecture provides resources like CPU, memory, and temporary storage to execute SQL SELECT statements that require computational resources for retrieving rows from tables and views. These virtual warehouses are Snowpark-optimized for faster query processing and come in different sizes to cater to different needs.
Use cases:
- Running ad hoc queries on large datasets
- Performing data transformations
- Generating reports
Snowflake-optimized Virtual Warehouse:
Snowflake-optimized virtual warehouses separate compute resources from storage, which makes them scalable and efficient. These virtual warehouses provide the best performance-to-cost ratio and can automatically scale up or down to match the computational requirements of the workload. They are available in different sizes, from X-Small to 4X-Large, to cater to different needs.
Use cases:
- Performing complex queries on massive datasets
- Running machine learning algorithms
- Processing large ETL workloads
Creating a virtual warehouse in Snowflake is easy and can be done through the web interface. The user can define the size, name, and other attributes of the virtual warehouse, and it can be scripted as well.
How Virtual Warehouses are Created and Managed
Virtual warehouses in Snowflake architecture can be created and managed by data engineers using the following steps and considerations:
- Creating a virtual warehouse: A virtual warehouse in Snowflake can be created through the web interface or by scripting a warehouse using SQL commands. When creating a virtual warehouse, users can specify its size, type (standard or Snowpark-optimized), and other attributes such as auto-suspend and auto-resume settings.
- Warehouse types: There are two types of virtual warehouses available in Snowflake architecture, standard and Snowpark-optimized. The standard warehouse provides the required resources, such as CPU, memory, and temporary storage, to perform SQL SELECT statements that require compute resources. In contrast, the Snowpark-optimized warehouse is designed to optimize performance for executing complex Snowpark ETL/ELT workloads.
- Warehouse management: Virtual warehouses in Snowflake can be managed by monitoring and adjusting their settings, such as size, auto-suspend, and auto-resume, to match the workload. When a statement requiring a warehouse is submitted, Snowflake automatically resumes the current warehouse for the session
- Limitations: It’s important to note that Snowpark-optimized warehouses have some limitations, such as not supporting Query Acceleration and not being supported on certain warehouse sizes. The creation and resumption of a Snowpark-optimized virtual warehouse may require more time compared to standard warehouses
Creating and managing a virtual cloud-based data warehouse in comparison to traditional data warehouses in Snowflake architecture involves defining its size, type, and other attributes, monitoring and adjusting its settings to match the workload, and considering limitations such as those of Snowpark-optimized warehouses.
Scaling Virtual Warehouses Up and Down
Snowflake provides the ability to scale up or down virtual warehouses, which are clusters of computing resources in Snowflake.
Here are some key points on scaling virtual warehouses in Snowflake:
- Types of Virtual Warehouses: The Snowflake warehouse provides two types of virtual warehouses, Standard and Snowpark-optimized, to perform various operations in a Snowflake session.
- Scaling Up: To scale up a virtual warehouse, users can resize the warehouse by increasing its size. Resizing a warehouse generally improves query performance, particularly for larger, more complex queries
- Scaling Out: If users need to expand a virtual warehouse, they can attach clusters to a multi-cluster warehouse, which mandates the Snowflake Enterprise Edition or a more advanced version. This warehouse enables several clusters to collaborate in processing queries, making it useful for managing sudden surges in workload
- Scaling Policies: To manage credits consumed by a multi-cluster warehouse operating in Auto-scale mode, Snowflake offers scaling policies that determine cluster start-up or shutdown. These policies only come into effect when the warehouse is running in Auto-scale mode.
- Considerations: When scaling virtual warehouses, it’s important to consider factors such as the size of the warehouse, the workload, and the number of users. It’s also important to monitor warehouse usage and credits to ensure efficient resource utilization.
Best Practices for Managing Virtual Warehouses
- Have dedicated virtual warehouses for different workloads such as loading, ELT, BI, reporting, and data science workloads as well as for other workloads to ensure efficient use of resources in data engineering.
- Consider using a no-code data pipeline like Hevo Data to automate data flow from different sources to Snowflake and other destinations without writing any code.
- Monitor user usage and service account usage in Snowflake using resource monitors to avoid exceeding credit quotas.
- Consider the workload requirements when creating a virtual warehouse and choose the appropriate size (e.g., X-Small, Small, X-Large) based on the required resources and the workload characteristics.
- Employ the automatic resume functionality to continue warehouse activities when a statement that necessitates a warehouse is entered and the said warehouse is currently active for the session.
Virtual warehouses in Snowflake architecture are essential for processing data workloads in the cloud. Standard virtual warehouses are optimized for faster query processing, while Snowflake-optimized virtual warehouses offer scalable and efficient compute resources. Companies can choose the type of virtual warehouse that best suits their specific needs and workload requirements.
Storage in Snowflake
Snowflake stores data in a highly compressed format, which allows for efficient use of storage space. It uses a multi-cluster shared data architecture, which means that data is automatically and transparently replicated across multiple data centers, providing high availability and durability.
Overview of Snowflake’s Multi-Cluster Shared Data Architecture
Snowflake’s multi-cluster shared data architecture is built from the ground up for the cloud, offering a unique approach to data warehousing. The architecture is based on the separation of the storage and compute layers, which allows each layer to scale independently.
This separation is achieved through the use of a virtual warehouse, which is a cluster of compute resources that can be dynamically scaled up or down as needed. Snowflake supports multi-cluster warehouses that enable the allocation of additional compute clusters, either statically or dynamically, to make a larger pool of compute resources available.
One of the benefits of Snowflake’s architecture is that it enables high concurrency, allowing multiple users and workloads to access the same data without contention which helps in streamlining data analytics requirements of data analysts. Another advantage is its ability to handle large volumes of data and to scale up or down seamlessly in response to changing workloads.
This architecture is delivered as a single, integrated platform-as-a-service (PaaS), which means that there is no need for infrastructure management or managing underlying software. Snowflake’s multi-cluster shared data architecture is designed to be easy to use, highly scalable, and cost-effective, making it a popular choice for the modern data warehousing and business intelligence needs of data scientists.
How Data is Compressed and Stored in Snowflake
Snowflake is a cloud-based data warehousing and analytics platform that provides various features for efficient data compression and storage.
Micro-Partitions
- Snowflake divides tables into smaller units called micro-partitions, which are typically 50-500 MB in size before compression.
- Micro-partitions enable efficient DML (Data Manipulation Language) and fine-grained pruning for faster queries.
- Each micro-partition is self-contained and contains metadata that describes the compressed data within it.
Data Compression
- The total storage used for an account is calculated by Snowflake through automatic compression of all data stored in tables based on their compressed file size.
- Columns are compressed individually within micro-partitions, using a combination of run-length encoding and Zstandard compression.
Data Clustering
- Snowflake supports the clustering of table data based on one or more columns, which groups related rows together in the same micro-partition.
- The clustering ratio is a measure of how well the data is clustered, with 100 indicating perfect clustering.
- Tables with well-clustered data can achieve better query performance and lower storage costs, as queries can skip over irrelevant micro-partitions.
Overall, Snowflake’s approach to data compression and as a storage service using micro-partitions and column-level compression enables efficient data processing, query performance, and storage management.
Replication and Redundancy in Snowflake
Snowflake’s architecture is designed to provide high availability, data redundancy, and replication capabilities across regions and cloud platforms.
Here are some key points about replication and redundancy in Snowflake’s architecture:
- Replication Across Multiple Accounts: Snowflake supports replicating databases between accounts within the same organization, allowing users to keep database objects and stored data synchronized.
- Data Replication Across Regions: Snowflake supports replicating data across regions within the same cloud platform, which allows for the creation of global applications with low-latency data access.
- Hybrid Architecture: Snowflake’s architecture is a hybrid of traditional shared-disk and shared-nothing database system architectures, allowing for high availability and scalability of data storage and compute resources.
- Redundancy: Snowflake maintains multiple copies of all data stored in its platform, with automatic replication of data across availability zones to ensure high durability and availability.
- Failover and Recovery: In the event of a hardware failure, Snowflake can automatically failover to a replica copy of the data to ensure minimal downtime and data loss.
- Compliance: When replicating a database to a different geographic region, users should confirm that there are no legal or regulatory restrictions on where their data can be hosted.
Overall, Snowflake’s architecture provides robust replication and redundancy features, ensuring high availability and durability of data for users.
Best Practices for Managing Data in Snowflake
Snowflake is a cloud-based data platform that offers a variety of features for managing and analyzing data. Below are some best practices for managing data in Snowflake:
Data Ingestion:
- Use a combination of COPY and Snowpipe for initial data ingestion.
- Keep file sizes above 10 MB and preferably in the range of 100 MB to 250 MB. Snowflake can support any size file, but keeping files below a few GB is better to simplify error handling and avoid wasted work.
Security:
- Use private DNS in your cloud provider network to allow the Snowflake account to be resolved from clients running both in the cloud provider network and on-premises.
Data Warehousing:
- Use virtual data warehouses to manage data. Snowflake recommends using a different virtual data warehouse for each use case and that users separate “loading” and “execution” into separate virtual warehouses.
These best practices are just a few of the many considerations to keep in mind when managing data in Snowflake. By following these guidelines, organizations can help ensure that their data is managed effectively and securely within the platform.
Exploring Data Loading and Unloading
Data can be loaded into Snowflake using a variety of methods, including bulk loading, streaming, and data ingestion. Data can also be unloaded from Snowflake using a variety of formats, including CSV, JSON, and Parquet.
- Security: Snowflake provides a range of security features to protect data, including encryption at rest and in transit, role-based access control, and multi-factor authentication. It also supports a range of compliance standards, including PCI DSS, HIPAA, and GDPR.
- Integration: Snowflake can be integrated with a wide range of third-party tools and services, including ETL tools, BI tools, and data integration platforms. It also provides a range of APIs and SDKs for programmatic access to data.
Methods for Loading Data into Snowflake
Snowflake offers various methods for loading data into its platform, including manual methods and automated methods.
Manual Methods
- Web Interface: Snowflake provides basic instructions for loading limited amounts of data using the web interface.
- COPY Command: Snowflake supports transforming data while loading it into a table using the COPY command. Options include column reordering, column omission, casts, and truncating text strings that exceed the target column length. Your target table does not necessarily have to share the same column order and count as your data files.
Automated Methods
- Snowpipe: Snowpipe is an automated service that continuously loads semi-structured data from files in an S3 bucket or Azure container into Snowflake. It allows for zero-copy loading and real-time data ingestion.
- Streaming Ingest: Snowflake also supports real-time streaming data ingestion using the Snowflake Java and Python clients.
Overall, Snowflake offers a range of methods for loading data into its platform, from basic manual methods to more advanced automated methods. Users can choose the method that best fits their needs based on factors such as data size, frequency of data updates, and data format.
Best Practices for Data Loading
Here are some best practices for data loading in Snowflake:
- Plan and design data loading: Before loading data into Snowflake, it is essential to plan and design the process to ensure that it meets the requirements and objectives. This includes determining data sources, file formats, transformations, data mappings, and data load scheduling.
- Consistent Granularity: When combining different granularities in the data solution, use power query or DAX to allocate the reference data appropriately, as sourcing data at a consistent granularity is important during the data loading and transformation process.
- Backup the data: Before executing the data loading process, backup the data to prevent data loss in case something goes wrong during the implementation. Ensure there are backup resources, and test them before proceeding.
- Use COPY and Snowpipe: Snowflake supports loading data in bulk using COPY and real-time data streaming using Snowpipe. COPY is the recommended way for bulk data loading, whereas Snowpipe is the preferred option for real-time data ingestion.
- Optimize File Size: Use file sizes above 10 MB and preferably in the range of 100 MB to 250 MB for initial data load using COPY and Snowpipe. Although Snowflake can accommodate files of any size, it is recommended to keep the files under a few GB to streamline error handling and prevent unnecessary work.
- Virtual Data Warehouses: Snowflake recommends using separate virtual data warehouses for each use case and separating “loading” and “execution” into different virtual data warehouses. This ensures that the data loading does not impact query performance.
Methods for Data Unloading
Snowflake offers various methods for unloading data, allowing users to export data from Snowflake tables and save it in various formats.
Here are some of the methods for unloading data in Snowflake:
- DML Commands: Users can use Data Manipulation Language (DML) commands to unload data from Snowflake tables. The ‘UNLOAD’ command can be used to export the result of a query to one or more files in an external stage location.
- COPY Command: Users can also use the ‘COPY’ command with the ‘UNLOAD’ option to unload data from a table into a file. This method is useful when users want to unload large amounts of data.
- External Tables: Users can create an external table in Snowflake that maps to the external data location. Once the external table is created, users can query the table to unload data.
- Snowpipe: Snowpipe is a continuous data ingestion service provided by Snowflake. Users can use Snowpipe to automatically unload and process data in real-time as it becomes available in external storage.
In summary, users can unload data from Snowflake using various methods such as DML commands, COPY commands, External Tables, and Snowpipe.
Summary and Key Takeaways
Snowflake has a distinctive hybrid architecture that combines traditional shared-disk and shared-nothing database architectures The architecture includes a storage layer, compute layer, and a cloud services layer, which enables high-performance data retrieval and analysis by organizing data into multiple micro-partitions.
Snowflake’s multi-cluster shared data architecture provides high concurrency and performance while separating the storage and compute layers, which provides greater flexibility and cost-effectiveness compared to traditional database warehousing solutions.
Virtual warehouses are a cloud-based solution for data warehousing that can be scaled up or down as needed. Snowflake is a popular virtual warehousing solution that uses multi-cluster shared data architecture to compress, store, replicate, and ensure redundancy in data.
Snowflake is a powerful cloud-based data warehousing solution that offers a unique hybrid architecture, virtual warehouses, and best practices for managing data. By following recommended methods and understanding the different types and their use cases, organizations can optimize their Snowflake experience and improve their data warehousing capabilities.
As you embark on your journey to leverage the full potential of Snowflake, remember that continuous learning is key. To deepen your expertise, we offer two comprehensive courses: Snowflake Fundamental Training for those starting their Snowflake journey, and Snowflake Advanced Training for those seeking to master its advanced capabilities.
By staying up-to-date with Snowflake’s ever-evolving capabilities and best practices, you’ll be well-prepared to harness the full power of this exceptional data architecture in your organization. Start your learning journey today and stay ahead in the world of data.
FAQs
1. What is Snowflake Architecture, and how does it differ from traditional database architectures?
Snowflake Architecture is a cloud-based data warehousing model designed for scalability and flexibility. Unlike traditional architectures, it separates storage and compute resources, allowing for on-demand scaling and efficient data storage.
2. What are the core components of Snowflake Architecture?
Snowflake Architecture consists of three core components: storage, compute, and services. Storage is responsible for data storage, compute handles query processing, and services manage metadata, security, and access control.
3. How does Snowflake handle data security and encryption?
Snowflake employs multiple layers of security, including encryption at rest and in transit, role-based access control, and fine-grained access policies. It also complies with various industry standards for data security.
4. Can Snowflake handle semi-structured and unstructured data?
Yes, Snowflake can handle semi-structured and unstructured data, making it suitable for analyzing a wide range of data types, including JSON, Avro, Parquet, and more.
5. What are the advantages of Snowflake’s data-sharing capabilities?
Snowflake’s data-sharing feature allows organizations to securely share data with external parties, enabling collaboration and monetization of data assets without copying or moving data.
6. How does Snowflake ensure high availability and data recovery?
Snowflake replicates data across multiple availability zones and regions, ensuring high availability. It also offers continuous data protection and automated data recovery mechanisms.
7. What are some common use cases for Snowflake Architecture?
Snowflake is commonly used for data warehousing, data analytics, business intelligence, data sharing, and data integration across various industries, including finance, healthcare, retail, and more.
8. Can Snowflake handle real-time data processing and analytics?
Yes, Snowflake supports real-time data processing and analytics through integration with streaming data sources and platforms, making it suitable for real-time decision-making.
9. How does Snowflake handle data transformation and ETL processes?
Snowflake provides native support for data transformation and ETL (Extract, Transform, Load) processes through its integrated Snowflake Data Pipelines, allowing for streamlined data processing.
10. How does Snowflake handle data governance and data lineage tracking?
Snowflake provides features for data governance, including metadata management, tagging, and data lineage tracking, helping organizations maintain data quality and compliance.
11. Can Snowflake be integrated with other data tools and platforms?
Yes, Snowflake offers integrations with various data tools, analytics platforms, and BI tools, allowing for a seamless and comprehensive data ecosystem.





{kind=link}