

Structured Query Language (SQL) is one of the most popular programming languages used by developers, data analysts, database administrators, and various other professionals working with data. With the continuously growing importance of data-driven decisions across every industry, the demand for SQL skills is at an all-time high.
Therefore, job seekers must be well prepared to face SQL interview questions. In this comprehensive guide, we have shortlisted 30 key SQL questions that are highly likely to come up in job interviews in 2024 across various roles. Read on to get detailed explanations and insights into each question.
- Top 30 SQL Interview Questions and Answers
- Q1. What is SQL?
- Q2. What are the different types of SQL statements?
- Q3. What are tables and columns in SQL?
- Q4. What are some SQL constraints you know?
- Q5. What are SQL indexes and why are they important?
- Q6. What is normalization in database design? What are its advantages?
- Q7. What is a view in SQL? What are the key benefits of using views?
- Q8. Explain different types of JOINS in SQL with examples.
- Q9. What is a subquery in SQL? Give an example showing where we can use them.
- Q10. How can you optimize slow SQL query performance?
- Q11. What are aggregate functions in SQL? Give 5 aggregate function examples.
- Q12. What is SQL injection? How can you prevent SQL injection attacks?
- Q13. How can you find the Nth highest salary from an “employee” table without using the TOP or limit method?
- Q14. Explain database transaction properties in SQL.
- Q15. What is the difference between a clustered index and a nonclustered index in SQL?
- Q16. What are CTEs in SQL? When would you use them?
- Q17. How do database indexes impact INSERT/UPDATE and SELECT queries?
- Q18. What are database constraints? Give examples of different constraint types.
- Q19. What are database relationships? Explain the different types of relationships with examples.
- Q20. When should you use NoSQL databases over traditional RDBMS?
- Q21. How can you handle Big Data challenges with SQL Server?
- Q22. What are database cursors? When would you use cursors?
- Q23. Explain different isolation levels in SQL transactions.
- Q24. How can you connect an SQL Server database with other data technology platforms like Hadoop, Spark, and Hive? What language extensions help achieve this?
- Q25. What is database partitioning in SQL Server? When should it be used?
- Q26. What is database replication? Explain different types of replication.
- Q27. How can you copy the structure of an existing table to create another table without copying the data?
- 28. Write SQL statements to add a default constraint, foreign key and check constraint on specific columns in a table.
- 29. Explain the concept of database normalization. What are its advantages?
- 30. How can you improve the performance of resource-intensive database queries?
- Conclusion
Top 30 SQL Interview Questions and Answers
Here are the top SQL interview questions:
Q1. What is SQL?
SQL (Structured Query Language) is a standardized programming language used for managing relational databases and performing various operations on the data in them. These operations include querying, inserting, updating, and deleting database records.
Designed for interactions with RDBMS, SQL provides a platform-independent interface to store and retrieve data efficiently. It enables developers to write SQL statements rather than low-level programming languages to interact with databases.
Q2. What are the different types of SQL statements?
SQL statements can be broadly divided into the following categories:
- Data Definition Language (DDL): Used to define the database schema and other objects inside the database. Some examples are CREATE, ALTER, DROP, and TRUNCATE.
- Data Manipulation Language (DML): Used to manipulate the data present inside the database objects. Some examples are SELECT, INSERT, UPDATE, and DELETE.
- Data Control Language (DCL): Used to control data access inside the database by granting or revoking user privileges. Some examples are GRANT and REVOKE.
- Transaction Control Language (TCL): Used for managing transactions, enabling the ability to roll back transactions and recover the database state before transactions. Some examples are COMMIT, ROLLBACK, and SAVEPOINT.
Q3. What are tables and columns in SQL?
Tables are the core building blocks of an SQL database which contain all the structured data stored across rows and columns.
Each column stores a particular attribute for that row item, with the same set of columns across rows defining the table structure. The column data types define the type of data values a column can store, like numbers, strings, dates etc.
For example, an “employee” table can have columns like employee_id, first_name, last_name, date_of_joining, salary etc.
Q4. What are some SQL constraints you know?

SQL constraints are used to define certain rules on table columns to prevent invalid data entry. This ensures data accuracy and integrity. Some commonly used constraints are:
- NOT NULL – Ensures a column cannot contain any NULL values
- UNIQUE – Ensures uniqueness of values in a column
- PRIMARY KEY – Uniquely identifies rows in a table, comprising uniqueness and non-nullability
- FOREIGN KEY – Ensures referential integrity between two related tables
- CHECK – Validates values against a boolean expression
- DEFAULT – Provides a default value for a column if no value is specified
Q5. What are SQL indexes and why are they important?
Indexes in SQL servers are performance-tuning structures associated with tables to facilitate faster retrieval of records while querying. They form pointer structures, storing only selective columns rather than entire rows.
Indexes enhance query performance as the database engine can rapidly locate rows fulfilling query conditions via indexes rather than scanning entire tables, especially in bigger databases.
However, indexes also impact write operations like inserts and updates. Hence indexes must be designed carefully based on typical system usage. The most commonly used indexes are clustered, nonclustered, and composite indexes spanning multiple columns.
Q6. What is normalization in database design? What are its advantages?
Normalization is the systematic methodology of organizing data to reduce data redundancy and improve data consistency across relational databases. It breaks down larger tables into multiple interconnected tables, each focused on distinct entities.
Advantages of normalization include:
- Minimizes duplicate data stored hence reduces storage overheads
- Enforces systematic design principles leading to fewer errors
- Enables easier expansions with minimal impact on existing structures
- Queries become faster due to reduced table complexity
The most common normal forms used are 1NF, 2NF, 3NF, and 4NF relating to the elimination of repeating groups, attainment of referential integrity, and further reduction of transitory dependencies.
Q7. What is a view in SQL? What are the key benefits of using views?
A view is a derived relational table formed by a stored SQL query. It represents a customized projection of underlying base tables selected by the view creator to suit their analysis requirements.
Views enable autonomy of data access without exposing confidential data attributes and provide data independence when base tables change. Views also simplify complex SQL queries for recurring reporting needs.
With no storage overheads, SQL views offer flexibility for data analytics by combining, filtering or restructuring columns from multiple tables using simplified and secured access paths.
Q8. Explain different types of JOINS in SQL with examples.
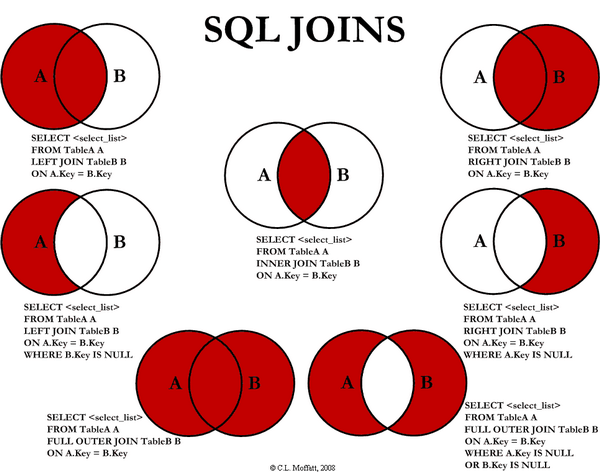
JOINS enables combining relevant data across SQL tables using matching columns, spawning a Cartesian product of qualifying rows. Various SQL JOINS include:
1. INNER JOIN: Returns only matching records from both tables, fusing columns into wider result sets. For example:
SELECT *
FROM Orders
INNER JOIN Customers
ON Orders.customer_id = Customers.id
2. OUTER JOINS:
- LEFT JOIN returns all records in the left table matched to the other table if criteria are met, else nulls.
- RIGHT JOIN returns matched records plus all records in the right table.
- FULL JOIN combines left join and right join. Outer joins prevent missing records.
3. SELF JOIN: Joins a table to itself using aliases e.g. joining Employees to their Managers using “id” and “mgr_id” aliases.
Q9. What is a subquery in SQL? Give an example showing where we can use them.
A subquery is an inner SELECT query nested within the main outer SQL query, connected using operators. Subqueries enhance code modularization. We can place subqueries at multiple locations like:
1. SELECT Column Expression e.g.
SELECT first_name,
(SELECT COUNT(*)
FROM orders
WHERE customer.id = orders.customer_id) AS orders
FROM customers
2. FROM clause in place of Joins e.g.
SELECT c.name, o.order_date
FROM
(SELECT * FROM customers) AS c,
(SELECT * FROM orders) AS o
WHERE c.id = o.customer_id
3. WHERE clause for row filtering e.g.
SELECT *
FROM employees
WHERE salary > (SELECT AVG(salary)
FROM employees)
Q10. How can you optimize slow SQL query performance?
Various ways to enhance SQL query performance include:
- Identifying performance bottlenecks using EXPLAIN plan, query execution runtimes
- Leveraging SQL indexes intelligently based on query filters and JOIN columns
- Refactoring complex long queries into simpler, modular, composable units
- Tuning costly table scan operations using filters and LIMIT clause
- Caching repetitive queries into temporary tables or views to avoid disk I/O
Additionally, database infrastructure level changes like using faster storage, adding memory, parallelizing queries etc. also improve speeds. Query optimizations require continuous performance tracking and refinements.
Q11. What are aggregate functions in SQL? Give 5 aggregate function examples.
Aggregate functions enable mathematical computations across a group of values in specific table columns to derive summarized statistical insights.
Commonly used SQL aggregate functions include:
1. SUM(): Sums all values
2. AVG(): Calculates average
3. MAX()/MIN(): Identifies maximum/minimum value
4. COUNT(): Counts rows
5. VARIANCE()/STDDEV(): Calculates variance and standard deviations
For example, calculating average customer wallet spend:
SELECT AVG(order_value) as avg_order
FROM orders;
Q12. What is SQL injection? How can you prevent SQL injection attacks?
SQL injection attacks involve malicious insertion of SQL code snippets via user input fields to gain unauthorized data access or corrupt databases.
Protection mechanisms include:
- Parameterized Queries: Substitute user inputs with parameters avoiding code injections
- Input Validation: Validate inputs to detect attack patterns
- Limited Privileges: Grant minimal database access to web applications
- Prepared Statements: Precompile SQL without injections for inputs binding
- Escape User Inputs: Escape special chars using security-centric libraries
Q13. How can you find the Nth highest salary from an “employee” table without using the TOP or limit method?
This can be achieved by leveraging the dense_rank function:
SELECT * FROM
(
SELECT e.name, e.salary,
DENSE_RANK() OVER(ORDER BY salary DESC) AS salary_rank
FROM employees e
) ranked_salaries
WHERE salary_rank = 2 — get 2nd highest salary
The inner query ranks salaries in descending order assigning the nth rank number to the nth highest salaried employee. Outer query filters on the rank number to only select the record with the desired nth highest salary, avoiding limits.
Q14. Explain database transaction properties in SQL.
A database transaction symbolizes a logical unit of work performed on a database to transition its state. Database theory defines four key transaction properties known as ACID:
- Atomicity: Ensures all operations within a transaction succeed or fail as an indivisible whole.
- Consistency: Any transaction shifts the database from one consistent state to another on completion.
- Isolation: Concurrent execution of transactions isolates their operations from each other until finished.
- Durability: After the transaction commits, changes persist and are not undone by system failure.
Q15. What is the difference between a clustered index and a nonclustered index in SQL?
Clustered indexes define the physical ordering of rows within SQL tables based on specified columns, ensuring the proximity of related data on disk for faster retrievals. Being physically stored, only one clustered index is allowed per table.
Nonclustered indexes maintain logical row ordering through reference pointers. They provide efficient seek and search operations without mandating physical structure. Multiple nonclustered indexes can hence coexist on tables as independent structures.
Q16. What are CTEs in SQL? When would you use them?
CTEs or Common Table Expressions represent temporary defined sets comprising a query statement that provides input to subsequent statements.
Use cases encompass:
- Simplify complex procedural logic using modularization
- Avoid duplicate queries via query reuse through reference
- Recursive code execution by referencing CTEs
For example, running totals query using CTE:
WITH cte_running_totals AS (
SELECT
ID, Date, Value,
SUM(Value) OVER(ORDER BY DATE) AS running_total
FROM Sales
)
SELECT *
FROM cte_running_totals;
Q17. How do database indexes impact INSERT/UPDATE and SELECT queries?
While indexes provide efficient row lookups, they also affect write performance, as index structures themselves need updates upon data modifications resulting in slower INSERT, UPDATE, and DELETE operations.
Index selection hence requires read vs write tradeoff evaluation, where predominantly read-heavy systems benefit via indexing for SELECT performance with negligibly impacted writes.
Transaction-oriented systems focused on writing rather than reporting eliminate indexes or design indexes cautiously.
Q18. What are database constraints? Give examples of different constraint types.
As the name signifies, constraints constitute automatic checks enforced on column values during INSERT and UPDATE database operations to preserve data integrity as per predefined validation rules and business logic.
Various SQL constraints include:
1. PRIMARY KEY: guarantees unique identification of records (NOT NULL & UNIQUE)
2. FOREIGN KEY: maintains cross-referential data consistency
3. UNIQUE: disallows duplicate values insistence
4. NOT NULL: averts NULL value allowed
5. CHECK: ensures boolean validation expression holds e.g. age > 18
6. DEFAULT: furnishes missing values with defaults
Q19. What are database relationships? Explain the different types of relationships with examples.
Table relationships provide associative linking between entities, indicating interdependency and cardinality i.e. how connected instances from both sides occur. Types of relationships include:
- One-to-one: Uniquely maps rows e.g. Country-to-President
- One-to-many: One record relates to multiple records e.g Country-to-Citizens
- Many-to-many: Multiple instances from both tables link e.g. Student-to-Courses (via bridge table)
Capturing these linkages via foreign keys enables uniform change propagation from master to dependent transactions.
Q20. When should you use NoSQL databases over traditional RDBMS?
While traditional RDBMS like Oracle, and MySQL shine in complex query execution and atomic transactions on structured data, NoSQL databases like MongoDB provide superior support for:
- Managing big unstructured/semi-structured data with flexible schemas
- Rapid prototyping using simple APIs instead of SQL expertise
- Horizontally scalable architectures across commodity machines
- Handling BLOBs like images requiring large storage
- Integrating JSON formatted web service data
NoSQL makes sense for hierarchical object storage, social media, IoT, and media streaming-based data models. SQL leads transactional systems.
Q21. How can you handle Big Data challenges with SQL Server?
While traditional RDBMS face Big Data limitations in flexibility, scalability, and performance, SQL Server provides several enhancements:
- Integrated PolyBase Technology parallelizing computation on Hadoop clusters
- Columnstore Indexes with batch processing mode GO exploiting wider rows
- Partitioned Tables splitting huge tables across storage partitions
- Resource Governor managing workloads between requests
- Automatic query parallelization utilizing multiple CPUs
These enable tackling volume, velocity, and a variety of challenges posed by immense, streaming, or unstructured Big Data.
Q22. What are database cursors? When would you use cursors?
Cursors represent database elements traversing result sets row-by-row, enabling procedural logic access across the rows, similar to programming language pointers.
Typical use arises for:
- Row-by-row dynamic SQL query generations
- Piecewise record processing prohibited by static SQL
- Encapsulating client-server database side transactions
For example, applying business rules row-by-row:
DECLARE @id INT, @name VARCHAR(100)
DECLARE cur_employees CURSOR FOR
SELECT id, name FROM employees
OPEN cur_employees
FETCH NEXT FROM cur_employees INTO @id, @name
WHILE @@FETCH_STATUS = 0
BEGIN
IF @id = 1
SET @name = CONCAT(@name, ‘(Manager)’)
UPDATE employees
SET name = @name
WHERE CURRENT OF cur_employees
FETCH NEXT FROM cur_employees INTO @id, @name
END
CLOSE cur_employees
DEALLOCATE cur_employees
Q23. Explain different isolation levels in SQL transactions.
Isolation levels define the extent of interference and effects of data modifications made by concurrent transactions on database consistency.
ANSI SQL defines 4 isolation levels:
- Read Uncommitted: Permits dirty reads of uncommitted, unvalidated data
- Read Committed: Provides consistency safety net by locking accessed rows
- Repeatable Read: Prevents non-repeatable reads via range locks
- Serializable: Highest protection via key range locking, ensuring serial execution
Weaker isolation improves concurrency while stronger levels enhance consistency. Selection depends on acceptable tradeoff needs.
Q24. How can you connect an SQL Server database with other data technology platforms like Hadoop, Spark, and Hive? What language extensions help achieve this?
Microsoft offers PolyBase technology utilizing distributed querying capabilities to seamlessly integrate and run analytics encompassing big data stored in Hadoop/Azure.
We can:
1. Import Big data using external tables into SQL Server
2. Export SQL Server data out to HDFS
3. Implement distributed cross-platform queries
Language components like T-SQL SELECT/FROM clauses transparently parallelize queries on both SQL engine and Hadoop clusters for catalytic price and performance gains.
Q25. What is database partitioning in SQL Server? When should it be used?
Partitioning entails the horizontal splitting of very large SQL Server tables across multiple smaller physical partitions stored as separate units to enhance manageability.
It proves beneficial for:
- Supporting partitions archival by hot-cold data classification
- Improving query performance via partition elimination
- Enabling parallel batch data loads and transforms
- Managing historical increasing data volumes more efficiently
We should hence partition big accumulate-over-time tables, like sales history, system logs etc. exceeding storage limits.
Q26. What is database replication? Explain different types of replication.
Replication automatically propagates committed data modifications from source databases to replica databases, ensuring transactional data redundancy.
Various replication types exist:
- Snapshot: Full dumps or differentials provide point-in-time data subsets
- Transactional: Committed transactions trigger incremental updates
- Merge: Designated databases consolidate data from multiple sources
Database replication safeguards analytics engines against failures through resilience while bolstering performance via parallelization. Replication, clustering, and mirroring represent high availability and scaled-out data mechanisms.
Q27. How can you copy the structure of an existing table to create another table without copying the data?
We can leverage the CREATE TABLE … LIKE technique to duplicate empty table structures from existing populated tables without copying over the actual rows, similar to a clone.
For instance, creating an empty clone of the customer’s table:
CREATE TABLE customers_empty
(LIKE customers);
The new duplicate table inherits the columns, data types, and constraints from the customer’s table, sans identity columns. This offers convenient templates for staging tables.
28. Write SQL statements to add a default constraint, foreign key and check constraint on specific columns in a table.
Adding table constraints illustrations:
— Add DEFAULT constraint
ALTER TABLE Orders
ADD CONSTRAINT default_order_type
DEFAULT ‘Online’ FOR order_type;
— Add FOREIGN KEY constraint
ALTER TABLE Orders
ADD CONSTRAINT fk_customer
FOREIGN KEY (customer_id)
REFERENCES Customers(id);
— Add CHECK constraint
ALTER TABLE Orders
ADD CONSTRAINT check_order_amount
CHECK (order_amount > 0);
29. Explain the concept of database normalization. What are its advantages?
Normalization organizes data to eliminate data redundancy, anomalies, and inconsistencies. It breaks large tables into smaller tables related to each other via relationships. Benefits include:
- Minimizes duplicate data
- Enforces data integrity
- Simpler queries and maintenance
- Better scalability
- Tightens security
Common normal forms are 1NF, 2NF, 3NF, and BCNF satisfying atomicity, entity integrity, referential integrity, and basis of key determination.
30. How can you improve the performance of resource-intensive database queries?
Methods to enhance the performance of complex SQL queries include:
- Query optimization using joins, indexes, aliases
- Query analysis to identify slow sections
- Parallelizing queries across multiple cores
- Caching frequently accessed query results
- Tuning poorly performing database tables
- Balancing memory and CPU allocations
- Upgrading to advanced hardware and fast I/O
Continuous query optimizations coupled with infrastructure enhancements deliver the best large database performance.
Conclusion
As data and analytics continue their inevitable growth across every industry, SQL skills will be in even greater demand in 2024 and beyond. These top 30 SQL interview questions and answers provide a solid foundation to prepare for the data roles of the future.
For those looking to become truly career-ready as data analysts, data engineers, or data scientists, a comprehensive bootcamp like CCS Learning Academy’s Data Analytics & Engineering Bootcamp is highly recommended. With its cutting-edge curriculum, hands-on projects, paid internship opportunities, and job placement assistance through 1-on-1 mentorship, the Bootcamp equips learners with both fundamentals and advanced data skills for the real world.
By mastering SQL along with Python, cloud tools, and other core areas, professionals can equip themselves for succeeding in data-driven roles spanning every sector. With data as the key driver of decision-making now, this is the right time to skill up!




